

Series Overview & ToC | Previous Article | Next Article
In the previous article, we learned how to migrate files. Today, we continue with two more entities: users and taxonomy terms. First, we’ll talk about preventing entity ID conflicts and water mark considerations. Then, we’ll discuss why our content migrations will not have dependencies on configuration migrations. Next, we’ll write the migrations for the two entities. Finally, we’ll cover stylistic choices we can leverage to make our migration files clean and compact.
Entity ID and high water mark considerations
Drupal 7’s user and taxonomy term entities are revisionable entities out of the box. Usually you would only have to review the users and taxonomy_term_data Drupal 7 database tables to determine the new AUTO_INCREMENT values in Drupal 10, but things are not so simple in our example project. Our migration plan dictates that nodes of type speaker should be migrated as user entities and nodes of type sponsor should become taxonomy term entities. In today's article, we are going to migrate users and taxonomy terms as they exist in Drupal 7. In the next one, we will take care of converting nodes to other entity types.
In Drupal 10, the user entity is still not revisionable, but the taxonomy entity was changed to store revision data. To determine the new AUTO_INCREMENT values for one entity in Drupal 10, you might need to review multiple entities and tables in Drupal 7.
For the base table of the user entity in Drupal 10, consider the highest user ID (uid) and node ID (nid) of speaker nodes in Drupal 7. For the base table of taxonomy_term entity in Drupal 10, consider the highest taxonomy term ID (tid) and node ID of sponsor nodes in Drupal 7. For the revision table of the taxonomy_term entity in Drupal 10 consider the highest taxonomy term ID and revision ID of sponsor nodes (vid) in Drupal 7.
Refer to article 23 for information on how to query the database to retrieve this information. The same article explains how to set the new AUTO_INCREMENT values in Drupal 10 via custom code and using the AUTO_INCREMENT Alter module.
For brevity, we are going to use the latter:
$settings['auto_increment_alter_content_entities'] = [
'user' => [350], // Alter the tables for the user content entity.
'taxonomy_term' => [200], // Alter the tables for the taxonomy term content entity.
];
Now execute the Drush command provided by the AUTO_INCREMENT Alter module to trigger the alter operation in the Drupal 10 project.
ddev drush auto-increment-alter:content-entities
To select the appropriate column for the high_water_property property, verify the available columns in the users and taxonomy_term_data tables:
DESCRIBE users;
DESCRIBE taxonomy_term_data;
Technical note: The high_water_property configuration option should be one of the columns returned by the source plugin. It is common that all fields for the primary source table are returned. That being said, a source plugin can provide more fields by performing JOIN operations on multiple tables or adding custom fields when preparing the row. This is how node migrations attach field API data to the records being fetched. Source plugins can also limit the fields to retrieve from a table or unset values that were already fetched. The drush migrate:fields-source command might help identify which fields are available. That is usually a static list and might not contain every possible option. One way to know for sure is available is to debug the migration.
For users, there are two possible columns to use. uid which stores the user ID and changed which stores the last time the account was updated. If you choose uid, incremental migrations will pick up new users, but they will not be able to update previously migrated users. This might be a problem if you need to run the Drupal 7 and 10 sites in parallel during a phased launch strategy. Changes to user accounts like credentials or roles updates will not be synced during incremental runs.
If you decide to use changed, new users and updates to existing users will be migrated. The caveat is that changed can contain duplicate values and that does not play well with the high water property. Under certain circumstances, the last saved value in the high water mark can match the value of records that still need to be processed. When this happens, the migration will skip some records. At the end of the migration, you will have pending records to process. This will prevent other migrations from running due to unmet dependencies. This problem might arise when running incremental migrations or when batching large migrations into smaller pieces. In such cases, implement a different optimization strategy.
For our example, we will proceed with changed for the high_water_property property in the user migration.
source:
key: migrate
plugin: d7_user
high_water_property:
name: changed
alias: u
In the case of taxonomy terms, Drupal 7 does not store information about when the entity was created or updated. The only viable option for the high_water_property property is the taxonomy term ID (tid):
source:
key: migrate
plugin: d7_taxonomy_term
high_water_property:
name: tid
alias: td
Dependencies on configuration migrations
We generated the content migrations back in article #10 using the Migrate Upgrade module. One key assumption of this approach is that all configuration migrations are executed, and their map tables are present, by the time the content migrations are executed. Because of this, many of the generated content migrations have dependencies on configuration migrations.
Our example project implemented various content model changes between Drupal 7 and Drupal 10. We used a combination of migrations, recipes, and manual configuration changes to build the new content model. Once the site was configured as needed, we deactivated the tag1_migration_config module, because the migrations alone did not reflect the final state of the site's configuration. Instead, we exported and updated configuration at different stages. The objective was to be able to install the site from the existing configuration. This gave us a fully configured site with no content that can be used as the starting point for our content migration efforts.
Re-installing Drupal from existing configuration means that the map and message tables that the migrate API uses to keep track of imports are no longer available. Lookup operations against configuration migrations will not work. This will require adjustments to the generated content migrations. It will be more work for us, but that will better reflect how custom migrations are performed. Replicating Drupal 7's configuration verbatim is rarely the goal of most real life migration projects.
To get started, we will have to update the migration_dependencies. We will also have to make adjustments to the process pipeline.
Migrating users
We use upgrade_d7_user to migrate users. Copy it from the reference folder into our custom module tag1_migration and rebuild caches for the migration to be detected.
cd drupal10
cp ref_migrations/migrate_plus.migration.upgrade_d7_user.yml web/modules/custom/tag1_migration/migrations/upgrade_d7_user.yml
ddev drush cache:rebuild
Note that while copying the file, we also changed its name and placed it in a migrations folder inside our tag1_migration custom module. After copying the file, make the following changes:
- Remove the following keys:
uuid,langcode,status,dependencies,field_plugin_method,cck_plugin_method, andmigration_group. - Add two migration tags:
userandtag1_content. - Add
key: migrateunder the source section. - Add the
high_water_propertyproperty as demonstrated above. - Map the
changedproperty in theprocesssection. This is optional, but we might as well migrate when an account was last updated if the data is available. - Update the migration dependencies so that only a required dependency on
upgrade_d7_fileremains.
In addition to the above, we need to make two more updates to the migration. First, our migration plan says that blocked users should not be migrated. In Drupal 7, the status column of the users table stores the relevant information. A value of 1 indicates the user is active while 0 means the user is blocked. We are going to use the skip_on_empty process plugin to prevent blocked users from being migrated:
process:
status:
-
plugin: skip_on_empty
source: status
method: row
message: 'User was not migrated because the account is blocked.'
Note: It is important to get familiar with process plugins available in Drupal core and contributed modules like Migrate Plus. We will demonstrate the usage of many throughout the series, but it is not practical nor feasible to cover them all. Read this documentation page to get acquainted with existing process plugins.
The second destination property that we need to update is roles. The generated migration attempts a lookup operation against the upgrade_d7_user_role migration. As explained earlier, this will not work. To address this situation, we need to know the IDs of the Drupal 7 roles. In article 3, we introduced a site audit template. Then, in article 8, we filled out the template with the help of document containing SQL queries to execute against the Drupal 7 database. Let's get the role IDs and update the role mapping accordingly.
SELECT rid AS role_id, name FROM role ORDER BY rid ASC;
process:
roles:
-
plugin: static_map
source: roles
map:
3: administrator
4: content_editor
bypass: TRUE
Let's break down how we end up with the above code snippet. In Drupal 7, roles were identified by an integer role ID (rid) value. In Drupal 10, roles are identified by a string machine name value. So, we need to map the Drupal 7 role id to the Drupal 10 role machine name. Pay close attention to possible name changes in roles. In Drupal 7, role id 4 was labeled Editor. In Drupal 10, the corresponding role's machine name is content_editor. Refer back to article #22 for context as to how this came to be.
The static_map process plugin can be used to make the necessary transformation from Drupal 7 role IDs to Drupal 10 role machine names. The usage of bypass is not needed in this case but was included for completeness. If there are roles that should not be migrated, you can exclude them from the assignment of the roles destination property. The static_map process plugin will throw an exception if it receives a value not present in the map configuration. To avoid this, we can let through any source role ID without a corresponding mapping. As long as there are no Drupal 10 roles matching such integer identifiers, there is no need to take extra measures to filter them out. The user save operation will only assign roles whose machine names exist in Drupal 10.
After the modifications, the upgrade_d7_user.yml file should look like this:
id: upgrade_d7_user
class: Drupal\user\Plugin\migrate\User
migration_tags:
- 'Drupal 7'
- Content
- user
- tag1_content
label: 'User accounts'
source:
key: migrate
plugin: d7_user
high_water_property:
name: changed
alias: u
process:
uid:
-
plugin: get
source: uid
name:
-
plugin: get
source: name
pass:
-
plugin: get
source: pass
mail:
-
plugin: get
source: mail
created:
-
plugin: get
source: created
changed:
-
plugin: get
source: changed
access:
-
plugin: get
source: access
login:
-
plugin: get
source: login
status:
-
plugin: skip_on_empty
source: status
method: row
message: 'User was not migrated because the account is blocked.'
timezone:
-
plugin: get
source: timezone
langcode:
-
plugin: user_langcode
source: entity_language
fallback_to_site_default: false
preferred_langcode:
-
plugin: user_langcode
source: language
fallback_to_site_default: true
preferred_admin_langcode:
-
plugin: user_langcode
source: language
fallback_to_site_default: true
init:
-
plugin: get
source: init
roles:
-
plugin: static_map
source: roles
map:
3: administrator
4: content_editor
bypass: TRUE
user_picture:
-
plugin: default_value
source: picture
default_value: null
-
plugin: migration_lookup
migration: upgrade_d7_file
destination:
plugin: 'entity:user'
migration_dependencies:
required:
- upgrade_d7_file
optional: { }
Now, rebuild caches for our changes to be detected and execute the migration. Run migrate:status to make sure we can connect to Drupal 7. Then, run migrate:import to perform the import operations.
ddev drush cache:rebuild
ddev drush migrate:status upgrade_d7_user
ddev drush migrate:import upgrade_d7_user
If things are properly configured, you should not get any errors. Go to https://migration-drupal10.ddev.site/admin/people and look at the list of migrated users.
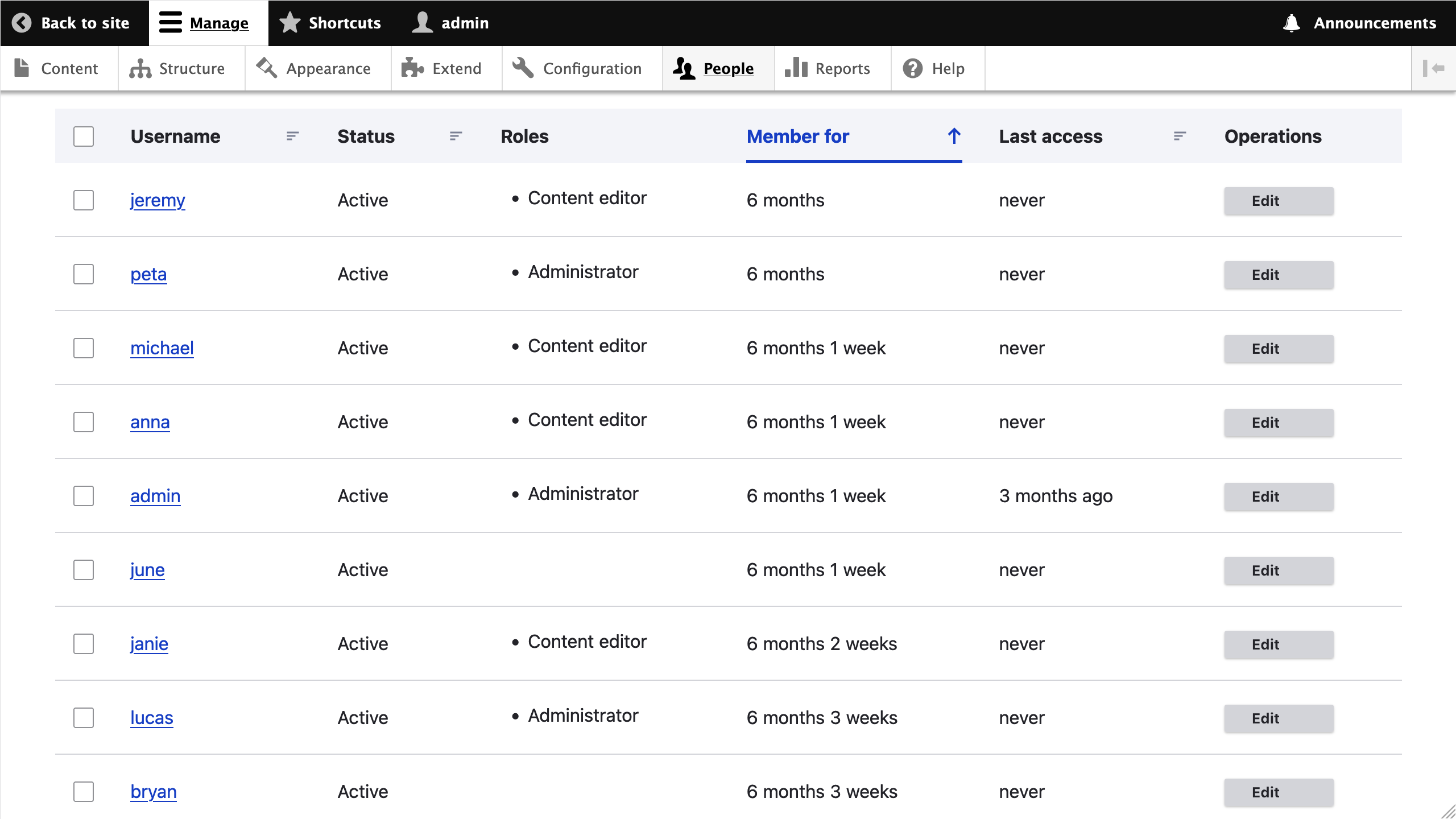
You can also see the messages related to users being skipped by running the ddev drush migrate:messages upgrade_d7_user --fields=source_ids,message or visiting the reports page at https://migration-drupal10.ddev.site/admin/reports/migration-messages/upgrade_d7_user. The source ID for the upgrade_d7_user migration is Drupal 7's user ID. The reports indicate that users with uid 10, 11, and 17 had their account deactivated.
-------------- -------------------------------------------------------------------------------
Source ID(s) Message
-------------- -------------------------------------------------------------------------------
10 upgrade_d7_user:status: User was not migrated because the account is blocked.
11 upgrade_d7_user:status: User was not migrated because the account is blocked.
17 upgrade_d7_user:status: User was not migrated because the account is blocked.
-------------- -------------------------------------------------------------------------------
Technical note: Source plugins need a way to uniquely identify each record to be processed. They implement the \Drupal\migrate\Plugin\MigrateSourceInterface::getIds method to get a set of one or more source fields, and their data types, that can be used for identification purposes.
Preventing records from being migrated
There are two common ways to prevent records from being migrated:
- Via the process pipeline.
- By modifying the query of the source plugin. See \Drupal\migrate\Plugin\migrate\source\SqlBase::query.
When using the process pipeline, we pass source data to process plugins to determine if a record should be migrated or not. This is what we did in today's example. When filtering out via source plugins, we add extra conditions to the SQL query that fetches the data. That way, unwanted records are removed directly by the source plugin without ever reaching Drupal.
Each approach has something in their favor. Filtering by modifying the source plugin’s query is more performant, because you are reducing the total number of records that need to be processed. This can lead to big performance gains when migrating large datasets. Filtering via the process pipeline is more flexible as you have access to Drupal APIs — and the whole PHP language — to implement the necessary logic that determines which records should not be migrated. This might be easier than modifying the source plugin's query to produce an equivalent exclusion logic.
Both are valid approaches. Implement the one that makes sense in each situation. We will demonstrate source plugin filtering when migrating media and node entities.
Migrating taxonomy terms
The automated upgrade process generates one migration for each Drupal 7 vocabulary. Having separate migrations is useful when each bundle of the content entity has a different set of fields. That is usually the case for content types, which are bundles of the node entity. Very often vocabularies, which are bundles of the taxonomy_term entity, do not have any field attached to them.
When migrating taxonomy terms:
- Use a single migration for all vocabularies that do not have any fields.
- Plus, one separate migration for each vocabulary that has one or more fields.
Our example project has two vocabularies: Session topics and Article Tags. None of them has fields so we will merge the two generated migrations into one. But first, let's compare the two generated migrations.
From the drupal10 folder, execute the following command:
ddev exec diff ref_migrations/migrate_plus.migration.upgrade_d7_taxonomy_term_session_topics.yml ref_migrations/migrate_plus.migration.upgrade_d7_taxonomy_term_tags.yml
The output of should be similar to:
1c1
uuid: cae873b1-70c6-4843-901d-9e2f0077e73a
---
> uuid: 0610670f-d2eb-40a0-a5b2-4ba51f750902
5c5
id: upgrade_d7_taxonomy_term_session_topics
---
> id: upgrade_d7_taxonomy_term_tags
13c13
label: 'Taxonomy terms (Session topics)'
---
> label: 'Taxonomy terms (Article Tags)'
16c16
bundle: session_topics
---
> bundle: tags
72c72
default_bundle: session_topics
---
> default_bundle: tags
Technical note: If you get an error after executing the diff command, it is fine to ignore it. When differences are found between the files being compared, diff will exit with status code 1. This is reported as an error by ddev exec, but in reality that is the expected result. You can suppress the error by running the command inside DDEV's web container (ddev ssh), by running the diff command from your host machine if it is available, or by redirecting the STDERR output to the /dev/null pseudo-device. Explaining this is outside the scope of the series.
Without context or a detailed explanation it is certainly hard to make sense of the diff command's output. Feel free to use a program that can provide visual differences between two files. Or better yet, check if your IDE of choice includes this functionality out of the box. Both PHPStorm and VSCode can compare files visually. Below is an image showing of leveraging a visual diff tool:
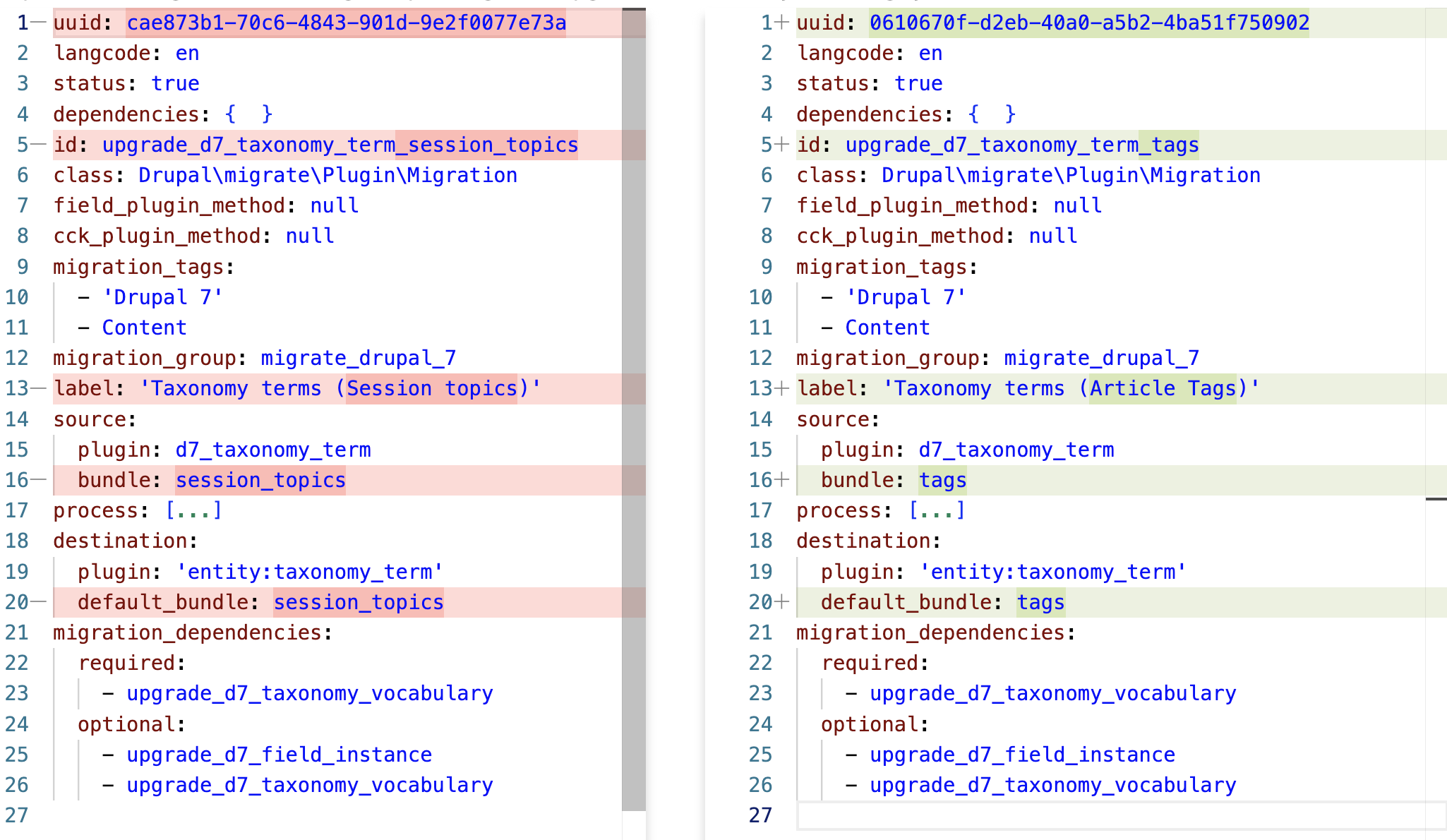
One way or another, it is clear that there are very little differences between upgrade_d7_taxonomy_term_session_topics.yml and upgrade_d7_taxonomy_term_tags.yml. Let's analyze each one:
-
uuidis a root property. It can be discarded when converting configuration entities to core migration plugins. -
idis a root property. For the combined migration we can useupgrade_d7_taxonomy_termas the migration ID. -
labelis a root property. For the combined migration we can useTaxonomy termsas the migration ID. -
bundleis a configuration option for thed7_taxonomy_termsource plugin. When set, it limits the vocabularies to fetch taxonomy terms from. For the combined migration we do not have to filter out any vocabulary.source/bundlewill be deleted. -
default_bundleis a configuration option for theentity:taxonomy_termdestination plugin. When set, it hints which vocabulary the taxonomy term that is being imported belongs to. For the combined migration we will use theviddestination property for this purpose.destination/default_bundlewill be deleted.
Technical note: The default_value configuration in entity destination plugin if there is a destination property for the entity’s bundle key. In the case of taxonomy terms, it would be the vid destination property. For nodes, it would be the type property. This is implemented in the \Drupal\migrate\Plugin\migrate\destination\Entity::getBundle method.
Merging taxonomy term migrations
Because the session_topics and tags Drupal 7 vocabularies do not have fields, we can have a single migration for both. We will use upgrade_d7_taxonomy_term_session_topics.yml as our starting point to migrate taxonomy terms. Copy it from the reference folder into our custom module tag1_migration and rebuild caches for the migration to be detected.
cd drupal10
cp ref_migrations/migrate_plus.migration.upgrade_d7_taxonomy_term_session_topics.yml web/modules/custom/tag1_migration/migrations/upgrade_d7_taxonomy_term.yml
ddev drush cache:rebuild
Note that while copying the file, we also changed its name and placed it in a migrations folder inside our tag1_migration custom module. After copying the file, make the following changes:
- Remove the following keys:
uuid,langcode,status,dependencies,field_plugin_method,cck_plugin_method, andmigration_group. - Change the
idtoupgrade_d7_taxonomy_term. - Change the
labeltoTaxonomy terms. - Add two migration tags:
taxonomy_termandtag1_content. - Add
key: migrateunder the source section. - Add the
high_water_propertyproperty as demonstrated above. - Remove the
bundlekey from thesourcesection. - Remove the
default_bundlefrom thedestinationsection. We will set theviddestination property. - Remove all migration dependencies.
Note: The d7_taxonomy_term source plugin can use an optional bundle configuration option. If it is missing, like what we are suggesting above, it will fetch all terms no matter the vocabulary they belong to. Alternatively, you can explicitly list one or more Drupal 7 vocabulary machine names to fetch terms from.
In addition to the above, we need to make two more changes to the migration. First, we need to update the mapping of the vid destination property. This is used to determine which Drupal 10 vocabulary the term being processed belongs to. At the moment, the mapping of vid uses a migration lookup against a configuration migration. As noted earlier in the article, we are not going to rely on configuration migrations being executed in the current installation.
Below is a snippet of the original mapping:
process:
vid:
-
plugin: migration_lookup
migration: upgrade_d7_taxonomy_vocabulary
source: vid
To replace the lookup operation, we can implement a static map similar to the one used for assigning roles in the user migration. In this case, we will map the integer vocabulary IDs from Drupal 7 to string vocabulary machines in Drupal 10. To obtain the map values refer to the filled out site audit template or execute the taxonomy term query against the Drupal 7 database.
SELECT
tv.module,
tv.vid,
tv.machine_name,
tv.name,
tv.description,
COUNT(td.tid) AS term_count
FROM taxonomy_vocabulary AS tv
LEFT JOIN taxonomy_term_data AS td ON td.vid = tv.vid
GROUP BY tv.vid
ORDER BY term_count DESC;
process:
vid:
-
plugin: static_map
source: vid
map:
1: tags
2: session_topics
Notice that we are not setting the bypass configuration in the static_map process plugin. When missing, a row will fail to import if the value of source property is not present in the map. In our case, this prevents creating a taxonomy term with an invalid Drupal 10 vocabulary. You can run the drush migrate:messages command to see the taxonomy term IDs of the records that are skipped for this reason. When this happens, we are either missing a vocabulary in the static map or the source plugin is fetching terms from vocabularies that we did not intend to.
Technical note: The d7_taxonomy_term source plugin used in the content migrations fetches the machine_name field from the taxonomy_vocabulary Drupal 7 table. In most cases, that value will match the machine name of the Drupal 10 vocabulary created by upgrade_d7_taxonomy_vocabulary configuration migration. If you review the vocabulary migration discussed in article #15, you will see that the vid property uses the make_unique_entity_field process plugin. This can lead to different vocabulary machine names between the two versions of Drupal. If you are certain that the machine names are the same, you can assign the vid property as follows: vid: machine_name. Otherwise, a static_map will get the job done.
The second change we need to make is to the parent_id pseudo-field. This is read by the parent destination property to indicate the parent term when a vocabulary has a nested hierarchy. Currently, the second transformation of its process plugin chain performs a lookup operation against all the generated taxonomy term content migration. We are customizing and merging these migrations into one. Therefore, we need to update the value of process/parent_id/1/migration to upgrade_d7_taxonomy_term, which is the ID of the migration we are writing. This means we have a migration that performs a lookup operation against itself to determine the parent taxonomy term.
Note: If a vocabulary is not hierarchical, the parent_id pseudo-field and the parent destination property can be removed altogether. When merging term migrations like in our example, do not remove them unless you are certain that none of the vocabularies being handled by the merged migration makes use of term hierarchies.
After the modifications, the upgrade_d7_taxonomy_term.yml file should look like this:
id: upgrade_d7_taxonomy_term
class: Drupal\migrate\Plugin\Migration
migration_tags:
- 'Drupal 7'
- Content
- taxonomy_term
- tag1_content
label: 'Taxonomy terms'
source:
key: migrate
plugin: d7_taxonomy_term
high_water_property:
name: tid
alias: td
process:
tid:
-
plugin: get
source: tid
revision_id:
-
plugin: get
source: tid
vid:
-
plugin: static_map
source: vid
map:
1: tags
2: session_topics
name:
-
plugin: get
source: name
description/value:
-
plugin: get
source: description
description/format:
-
plugin: get
source: format
weight:
-
plugin: get
source: weight
parent_id:
-
plugin: skip_on_empty
method: process
source: parent
-
plugin: migration_lookup
migration:
- upgrade_d7_taxonomy_term
parent:
-
plugin: default_value
default_value: 0
source: '@parent_id'
changed:
-
plugin: get
source: timestamp
langcode:
-
plugin: get
source: language
destination:
plugin: 'entity:taxonomy_term'
migration_dependencies:
required: { }
optional: { }
Now, rebuild caches for our changes to be detected and execute the migration. Run migrate:status to make sure we can connect to Drupal 7. Then, run migrate:import to perform the import operations.
ddev drush cache:rebuild
ddev drush migrate:status upgrade_d7_taxonomy_term
ddev drush migrate:import upgrade_d7_taxonomy_term
If things are properly configured, you should not get any errors. Go to https://migration-drupal10.ddev.site/admin/structure/taxonomy/manage/tags/overview and https://migration-drupal10.ddev.site/admin/structure/taxonomy/manage/session_topics/overview to see the migrated terms in their corresponding vocabularies.
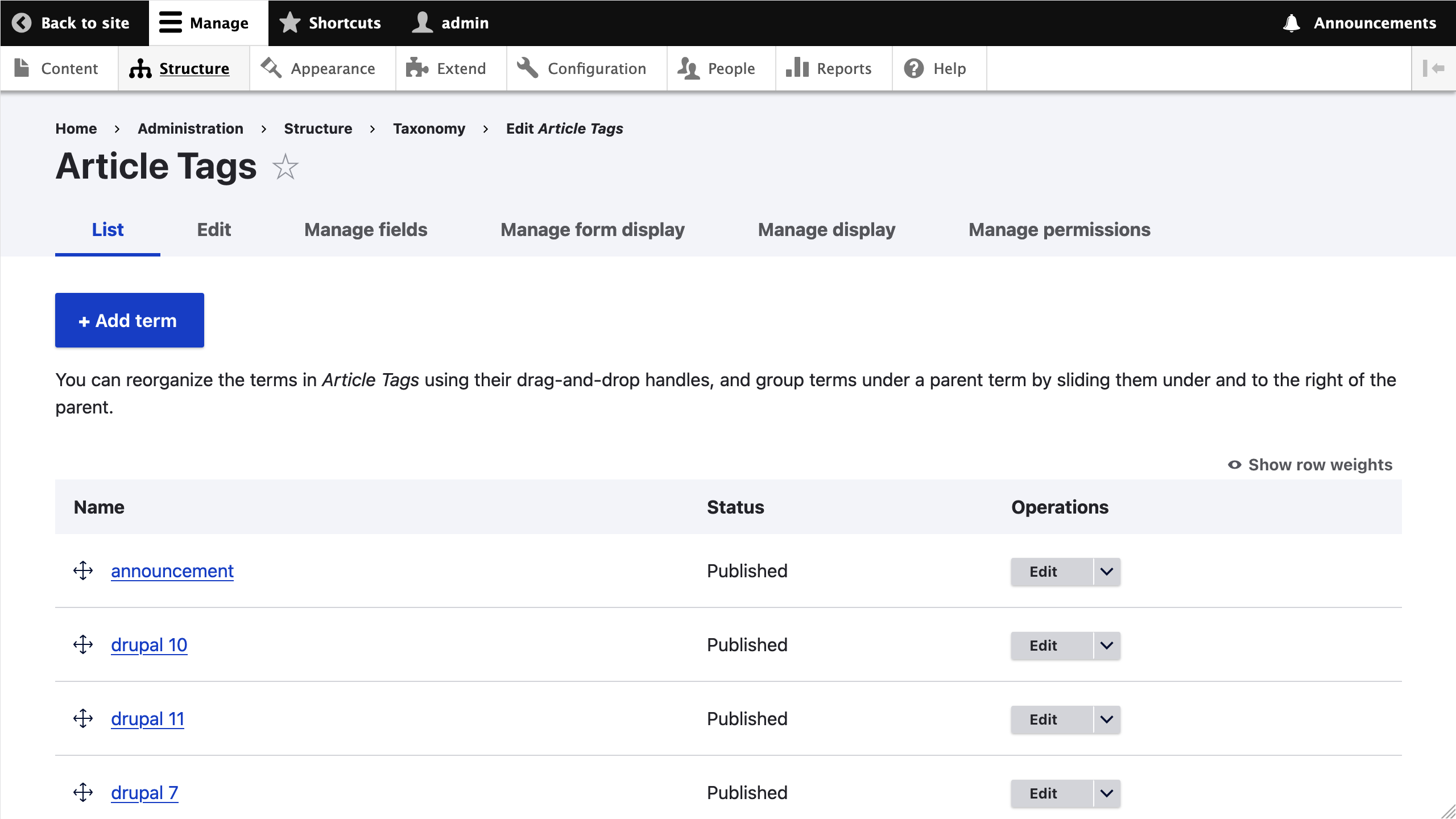
Clean and compact migrations
Before closing, I would like to acknowledge that the two migrations we wrote in this article are not as clean and compact as they could be. The former refers to a migration cleaned of unnecessary destination properties. The latter refers to using syntactic sugar in the migration files to make them more compact and easier to read.
Consider this alternative process section for the upgrade_d7_taxonomy_term migration:
process:
tid: tid
revision_id: tid
vid:
plugin: static_map
source: vid
map:
1: tags
2: session_topics
name: name
description/value: description
description/format: format
weight: weight
changed: timestamp
langcode: language
The parent_id and parent destination properties are removed because none of our vocabularies are hierarchical. In the case of the upgrade_d7_user migration, we could have removed the user_picture destination property and the corresponding dependency on upgrade_d7_file, because none of Drupal 7 users had a picture associated with them. Removing unnecessary destination properties requires an understanding of the project requirements and the source data. It is not possible for us to give generalized advice on this matter. Carefully review any destination property that you are planning to remove to make sure it is indeed not needed.
In the snippet above, all destination properties that use a single get process plugin are reduced to a one-line mapping. The vid uses a single process plugin so there is no need to use an array syntax for it. This syntactic sugar makes the migration files more compact. I would also argue that this format is easier to read. Whichever style you use, be consistent throughout the whole project. Above all, favor what would make it easier for you and your team to understand what the migration is doing. Ultimately, you are the ones responsible for maintaining the project.
In the next article, we will learn how one entity type in Drupal 7 can be migrated into a different entity type in Drupal 10. That is useful when we need to implement content model changes.
Contact Our Solutions Experts
Helping you navigate the next steps on your Drupal Migration Journey
Image by Dimitris Vetsikas from Pixabay